Why I Stopped Adding to the Shared Script
The change would've probably worked. That's what made it dangerous. Why I duplicated a Boomi validation script instead of extending another shared abstraction.
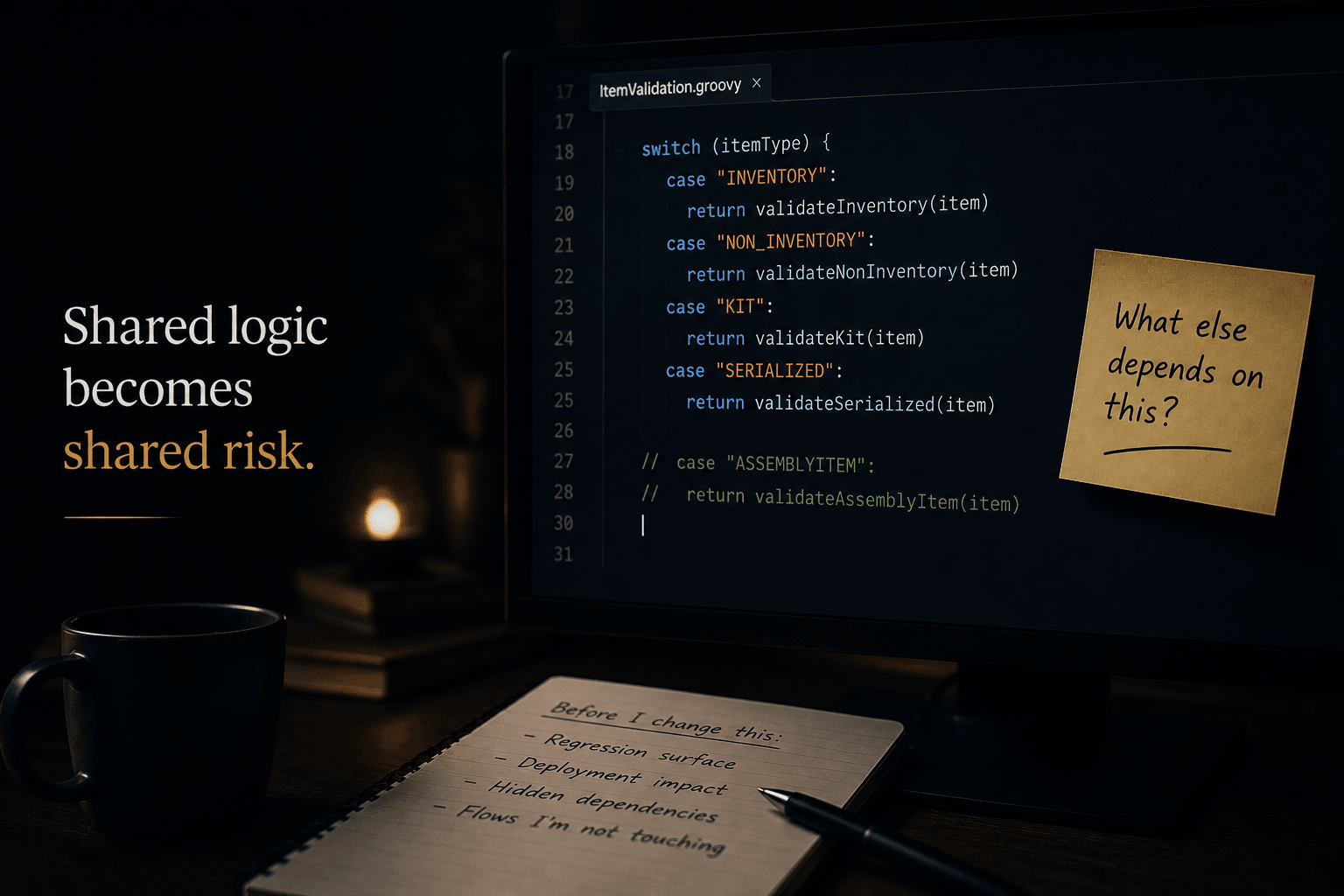
Why I Stopped Adding to the Shared Script
The shared Groovy validation script in Boomi was originally written for inventory items.
Not inside some giant shared process. Just a common script shape reused across multiple item flows because the validation logic started out nearly identical.
Then other item types got bolted on over time. Non-inventory. Kit. Serialized. AssemblyItem was supposed to be next.
I wrote a separate script instead.
The change itself wasn't tiny — bigger than the "just add an if-block" make-believe people pretend these things are. But that wasn't the point. The point was that it could have been bolted on. The pattern was already there. Other item types were already living inside that script. Adding another wasn't reckless. It was the obvious move.
That's exactly why I didn't do it.
Here's the math nobody runs.
Even though it wasn't a shared process, the script had effectively become shared infrastructure. Every item flow running it was behaviorally coupled to the same logic, the same assumptions, the same deployment cycle. Changing the script wasn't changing one flow anymore. It was changing every flow that implicitly trusted its existing behavior.
That's the real blast radius people miss.
The test surface stops being your new logic. Now you're regression testing every item integration that runs the shape — inventory, non-inventory, kit, serialized. You're not adding a branch anymore. You're proposing a redeploy of a core dependency sitting underneath half the item layer.
And the dangerous part is that the change would probably work.
That's what makes these situations expensive.
The AssemblyItem validation passes testing.
The deployment goes out.
Nothing breaks.
Everything looks fine.
Then three days later another item flow starts behaving differently because it depended on some normalization quirk in the script that nobody knew was load-bearing.
Now someone is diffing process executions at 11pm asking the worst question in integration work:
what else touched this script?
Senior engineering does both.
Reuse where it pays.
Containment where it protects.
The judgment is knowing which one the situation actually wants.
Integration work is unforgiving — one detail off and you've nuked the flow.
So instead of extending the common validator again, I duplicated the boilerplate and isolated AssemblyItem validation into its own script.
Less DRY, yes.
Safer in production, by a long way.
The deployment boundary now matches the business problem.
If AssemblyItem validation breaks, AssemblyItems break.
The other item flows keep running.
Order syncs keep running.
Everything else keeps moving.
That's a survivable failure domain.
People talk about DRY like it's a law.
It's not.
It's a heuristic.
The real rule is:
duplication is cheaper than the wrong abstraction
The script started as inventory validation.
Every additional item type pushed the abstraction further from what it originally was.
By the time AssemblyItem showed up, the validator wasn't really a validator anymore.
It was a shared integration dependency pretending to be simple reusable code.
And that's where I stopped adding to it.
A separate script costs me a few hours of duplicated boilerplate.
It gives the AssemblyItem flow its own deploy cadence, its own failure mode, and its own ownership boundary.
That's the whole point.
The senior version of this job isn't writing clever code.
It's protecting the code you're not touching.
Written by the team at Adaptive Solutions Group — NetSuite consultants based in Pittsburgh, PA.